
Scrapping des avocats du Barreau de Rennes
Ma curiosité naturelle m'a amené à découvrir le scraping grâce aux vidéos de Shubham Sharma, ancien employé de Qonto, sur sa chaîne YouTube. Il y présente des outils comme DataMiner pour extraire des données de sites web.
Cependant, j'ai remarqué que ces extensions Chrome ne fonctionnaient pas toujours de manière optimale, certaines informations n'étant pas correctement récupérées.
Souhaitant trouver une solution plus fiable, j'ai exploré d'autres méthodes de scraping et découvert BeautifulSoup4, une bibliothèque Python qui semble répondre à ce que je souhaitais faire.
Apprendre à scrapper un annuaire en python
Avril 2024
Annuaire Barreau de Rennes
Explication
Pour approfondir mes compétences en scraping de sites web plus complexes, je me suis intéressé aux différentes techniques disponibles. Python, avec la bibliothèque BeautifulSoup4, revenait souvent dans les ressources que j'ai consultées. Mes connaissances en HTML/CSS, acquises lors de ma formation à l'EFREI, constituaient une base solide, même si je n'avais jamais pratiqué Python.
L'utilisation de l'intelligence artificielle générative, comme Codestral, m'a semblé être une opportunité pour accélérer mon apprentissage. J'ai commencé par visionner des tutoriels sur YouTube pour comprendre les bases du scraping avec Python : l'importance de ménager les serveurs en espaçant les requêtes, l'utilisation d'un "user-agent" pour éviter d'être bloqué, et l'identification des éléments à extraire grâce à leurs classes ou XPath.
Pour me familiariser avec ces concepts, j'ai choisi l'annuaire du Barreau de Rennes comme cas pratique. J'ai repéré les classes HTML correspondant aux informations recherchées (nom, prénom, adresse, email) afin de constituer une liste de contacts.
Muni de ces éléments, j'ai rédigé un prompt détaillé pour Codestral, dans l'objectif d'obtenir un script Python fonctionnel, quitte à l'adapter par la suite.
Résultat
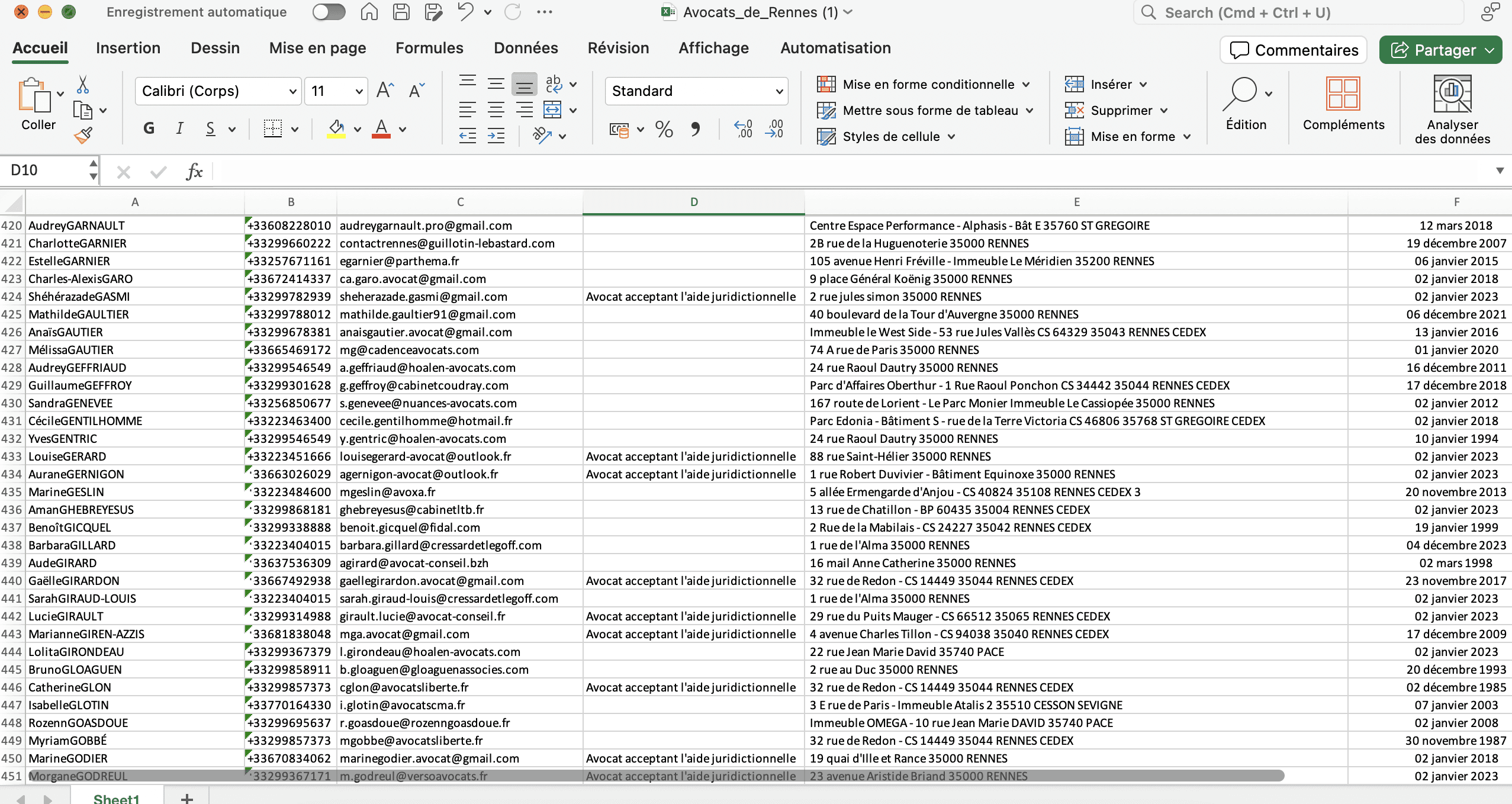
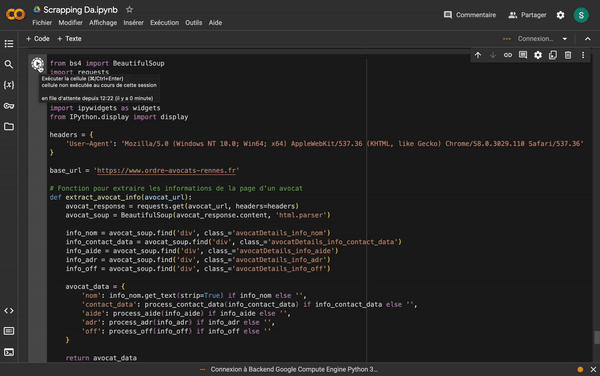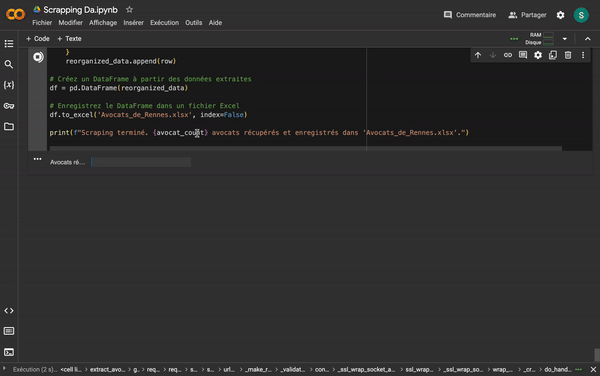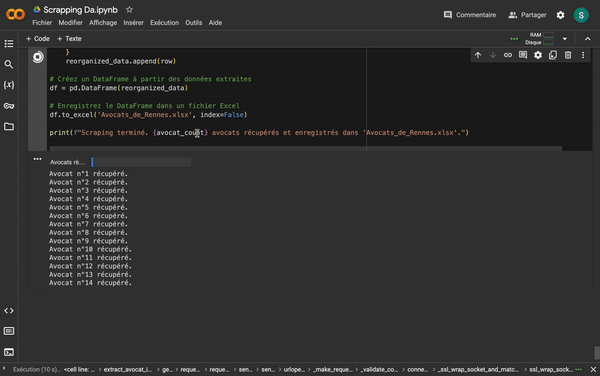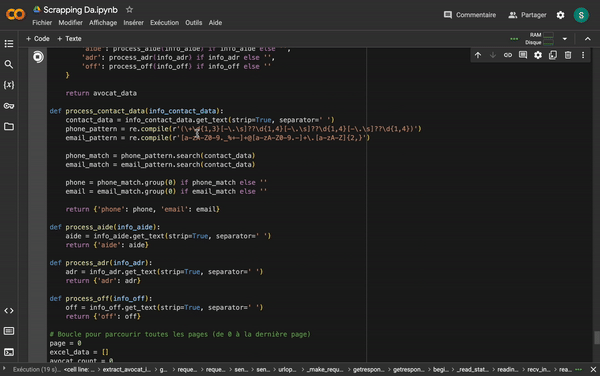
Après quelques échanges avec Codestral, j'ai réussi à obtenir un code Python fonctionnel que j'ai exécuté sur Google Colab Research. En quelques minutes, j'ai extrait 1041 lignes de contacts dans un fichier Excel, prêtes à être nettoyées. Cadeau si vous les voulez :)
1041
Lignes de contacts
+1
Langage de programmation étudié
22min
Temps pour que le code arrive au bout de l'annuaire du site
Conclusion
Ce genre de défi renforce mon intérêt pour les outils digitaux et me prouve que même face à des problématiques liées au code, la persévérance finit par payer.
En tant que futur professionnel du marketing, je considère qu'avoir des bases en web scraping est essentiel, non seulement pour l'acquisition de leads, mais aussi pour d'autres aspects comme la veille concurrentielle.
De plus, la dimension "code" m'attire particulièrement, car la logique est souvent similaire d'un langage à l'autre. Ces compétences me seront utiles, notamment pour comprendre le code HTML en SEO technique ou pour concevoir des emailings HTML.